I’d like to discuss a paper we’ve published lately. The paper presents work done at Elastifile.com, building a new kind of consensus algorithm. Before describing what our new system does, let’s see why previous consensus algorithms weren’t sufficient.
Most consensus algorithms, like Paxos (which I’ve discussed previously in this blog, here and here), Raft or Zab (used in ZooKeeper), are based on the concept of “state machine replication” (SMR). Such algorithms reach agreement on a distributed log, which represents state transitions. Given an initial state, and the distributed log, the current state can be reached by “replaying” the log entries one after the other. Since the initial state is known to the servers, and since the distributed log is achieved via consensus, it is also known to the servers. Thus, if one node P fails, some other node Q can continue from where P left off.
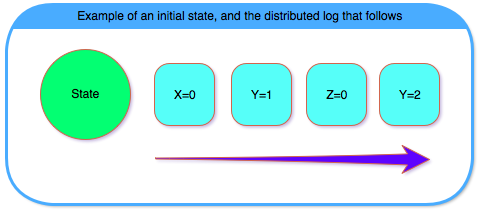
There are a few drawbacks to distributed log based consensus algorithms. First, if some log entry is taking more time to commit, for example due to a slow disk IO, or due to a packet drop, all following log entries must wait for it. That is, inserting “y=1” to the log blocks the execution of “z=0”, even though they might be unrelated. (Note that “z=0” can be added to the log before “y=1” is committed, but we can’t replay “z=0” until “y=1” has been replayed). This means that a slow operation will delay all following operations, whether they depend on it or not.
Second, when recovering from failures, we need to recover the distributed log entirely before the most up to date state can be constructed. That is, for us to replay the transition “z=0”, we must first replay “x=0” and “y=1”. This means that if there is a query about z, we need to wait for the entire log to be recovered before we can respond.
Third, due to the longer recovery times, the timeout to detect failures is set to be longer. That is, the higher the cost of false detection of a failure, the longer we want to wait before reelecting a leader. This means that if a node really failed, a new election will kick in after a longer timeout, and during that time, no requests will be served.
These drawbacks (and some others, presented in the full paper) have led us to develop Bizur, which is a key-value consensus algorithm. It allows for operations on different keys to operate concurrently (an example can be seen in the image bellow), thus mitigating the aforementioned drawbacks of distributed-log based consensus algorithms.
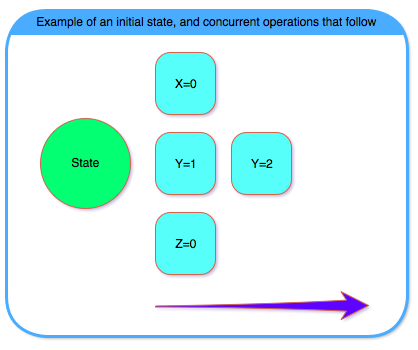
The main idea behind Bizur is to utilize the key-value data model. Different keys are independent of each other, and as such we can handle requests on them independently. Thus, Bizur can forego the distributed log, and instead use something more similar to shared registers (again, more details in the full paper).
The reason that Bizur can improve upon Paxos / Raft / Zab is because those algorithms work for every kind of data model, while Bizur is limited to the key-value data model only. Surprisingly, some well known services like ZooKeeper or etcd utilize under the hood a distributed log kind of consensus algorithms, while their data-model is a key-value one.
We’ve compared Bizur to ZooKeeper and etcd during leader failure, by killing the node that is the leader, and plotting the throughput and latency of requests before and after the failure. As can be seen in the graph below, Bizur behaves very nicely in this situation.
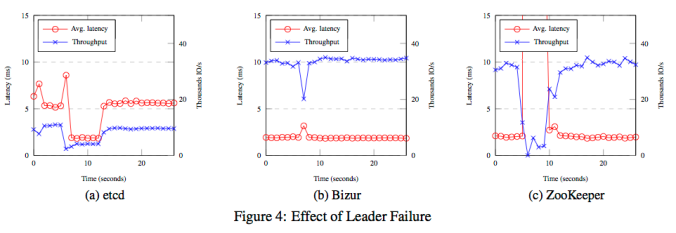
In the full paper you can read more about how Bizur is implemented, about its scalability, and see more comparisons with etcd and ZooKeeper.

Very nice! Surprising this wasn’t done before.
Q: how hard would it be to add consistent constraints between keys, to allow a more flexible schema?
Thanks.
A: Multi-key transactions (allowing any kind of constraints between keys) can be implemented as an additional layer (using algorithms like 2PC, etc.). However, if many of the operations require multi-key transactions, then it might be more efficient to use the regular kind of consensus for the entire system.
Since in our use-case we don’t need multi-key transactions at all, we haven’t experimented with that direction. It would be interesting to see how such an additional layer would compare with other systems.
Things like this have been done before.
Can you elaborate please? Link or reference?
Is the source for bizur open ?
No, the source code for Bizur is internal to Elastifile.
Pingback: The engineering of Elastifile - Storage Gaga
Pingback: Log-less Consensus | Distributed Thoughts
So, Bizur paper is on public domain. Can I implement Bizur without getting into patent problems? Because in the Elastifile they says there tech is patented.
This is my personal blog, and I can’t give an official answer.
With that caveat in mind, you can implement Bizur for non-commercial purposes. However, since Bizur’s IPR are owned by Elastifile, any commercial usage of the technology needs to be officially licensed by Elastifile.
Pingback: Always serendipitous Storage Field Days – Storage Gaga
Pingback: StorageOS reinvents VSAN for containers – Blocks and Files - Tech Box