Since most people know of log-based consensus, like Paxos or Raft, it is easier to describe log-less consensus by comparison to log-based consensus.
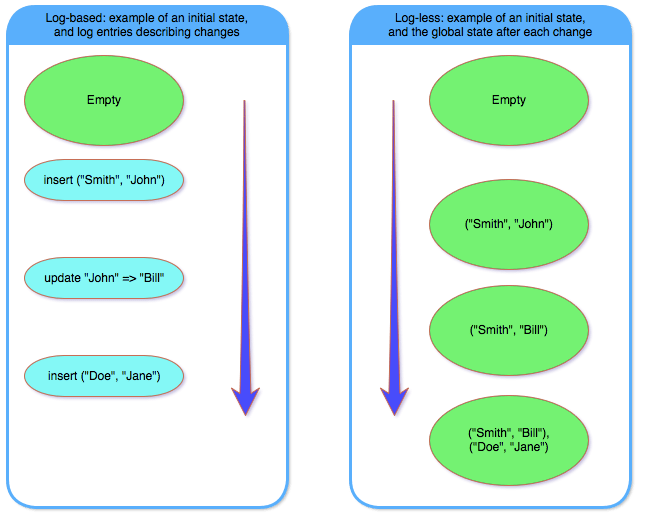
In log-based consensus, the system keeps a global state which evolves over time. The state is evolved by tracking the actual changes of the global state. For example, the global state might be the content of some database, and the changes would be inserts / updates / deletes performed on the database. Each such change is encapsulated as a “log entry”, and inserted into the log. The new global state can be derived from the previous global state, plus all the entries in the log.
Since changes are captured by appending log entries to the log, eventually the log becomes too large, and requires “compaction”. Log compaction consists of building a new global state (composed of the old global state, plus the changes in the log), and clearing the old entries from the log.
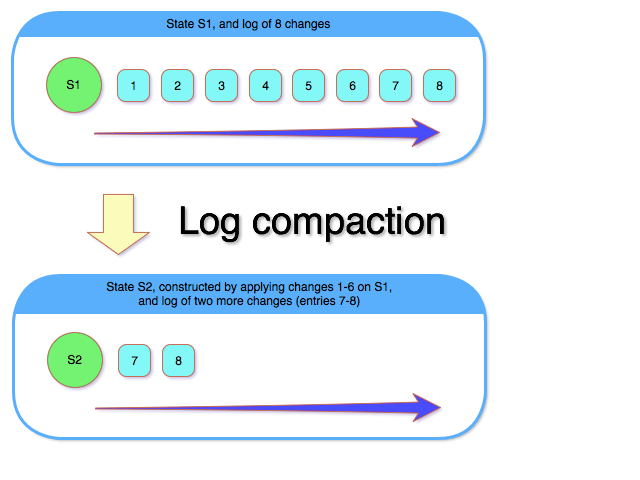
Log-less vs. Log-based Consensus
Log-less consensus, on the other hand, doesn’t have a log. Each change, occurs on the global state as a whole. There is no log that records the changes, but rather the global state is updated “in-place”. Thus, in a log-less consensus, there is just a global state that changes over time, while in a log-based consensus there is a global state that is “fixed” (until compaction) and a log – representing changes – that is appended over time.
When the global state is large, log-less consensus can be very inefficient. Taking the above database example to an extreme, if the database is 1GB in size, each further change will be sending the entire 1GB data over the network. As I said, very inefficient.
However, when the global state is small, the complexity overhead of the log-based consensus (managing the log appending, log compaction, etc.) isn’t worth it. For example, if the global state is an S3 handle, pointing to some configuration file, it makes more sense to have a log-less consensus storing that information.
So there is a nice tradeoff here, between log-less and log-based consensus. The former is much simpler, but is inefficient for anything but small states, while the latter is very complex but is fairly efficient for all state sizes.
Log-less Consensus in Action
We can say log-less consensus consists of having a group of servers agree on a single value, which is updated over time while preserving linearizability, in a fault-tolerant manner. Both Bizur and gryadka are based on log-less consensus, each with its own implementation. Bizur uses a construct similar to a shared-memory register with a leader-election in front of it, while gryadka uses an extension of the single decree Paxos (a.k.a. Synod).
For the purpose of evaluating the benefits of log-less consensus, it doesn’t really matter what internal implementation is used; especially since both implementations preserve the quality of being much simpler than log-based consensus.
So where can log-less consensus be used?
In scenarios where the size of the global state is small. I can think of two such settings:
a) small configuration information / DB, and b) key-value store. The first scenario is fairly self-explanatory, so let’s concentrate on the second one.
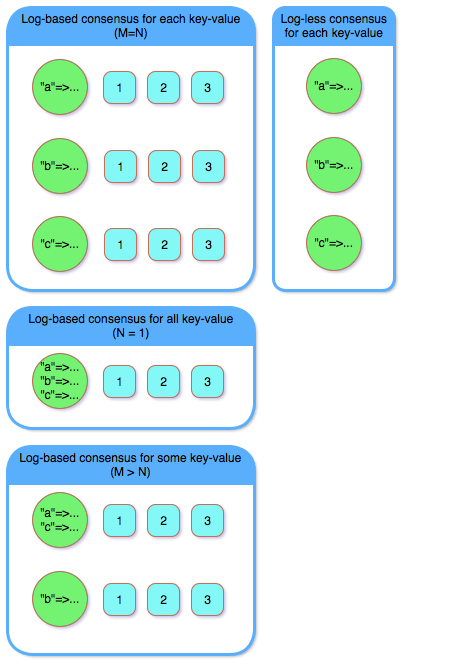
A key-value store might be very large, so at a first glance, it doesn’t fit well with “the global state is small” statement. However, we can think of each key-value pair as its own global state. That is, assuming key-value pairs are changed independently (i.e., no multi-key transactions), each can be treated as a separate consensus entity. By handling each key-value pair independently, the scalability and concurrency of the key-value store are increased drastically.
A good way to see this, is by comparison with the log-based consensus. The “default” usage of a log-based consensus to build a key-value store would be: having a single global state encompassing the entire database. Clearly, such a solution would have scaling and concurrency issues, since every operation must be appended to the same log.
An alternative solution would be to have a log-based consensus per key-value pair, which would work but be inefficient, since we’d need to manage a log for each key-value. Why have the log overhead (both code-wise and runtime-wise) when a log-less consensus would work just as well?
A third alternative is somewhere in between: keep multiple log-based consensus, but not one for each key-value pair. That is, M key-value pairs will be mapped into a N log-based consensuses, where M > N. Such a solution amortizes the overhead of log-based consensus over multiple key-value pairs, increasing the runtime utilization of resources. However, since the runtime overhead of log-less consensus is very low, it is still a much simpler solution than this alternative.
TL;DR;
Log-less consensus makes a lot of sense for key-value stores, as can be seen from the following diagram.
Disclaimer
Once we want to also delete key-value pairs, things aren’t as simple as described above. A simple solution would be to write something like “key=>NULL” to mark the key-value as deleted. However, that would still leave some space for each deleted key-value. To reclaim all the space back, we’d need to delete the consensus instance that keeps the state of the key-value we’re deleting.
That’s harder than it sounds – I hope to write a post detailing why. For now, I’ll just say that a) using a single log-based consensus doesn’t have this problem at all, as well as using the M > N variant (with N a static value); and b) it is possible to resolve the “deletion problem” in an efficient way, you can take a look at how Bizur solves it (blog post and full paper).
