Update June-28: Thanks to Eyal for finding a bug and suggesting a fix (already incorporated into the post).
Let’s consider a simple service that has two main operations: read and write. We expect the service to persist the value passed in write and retrieve it when calling read. Making this service fault tolerant is non-trivial, and encapsulates many interesting problems. Due to its simplicity, it is a good example of a distributed system we can investigate.
In some cases, there are assumptions we can introduce to simplify the high-availability and fault tolerance of a distributed system. An example of such an assumption is the single-writer assumption, which means that at any given point there is at most one writer in the system. Under this assumption, we can achieve fault-tolerance for our service within a single round-trip, using a very simple majority-based algorithm.
The Setup
Before we delve into the details, let’s go over the players. We have two main types of components: controllers and datastores; and two types of failures: power-failure and hardware failure. You can think of a controller as a CPU plus memory, while a datastore is a CPU plus disk. Both are connected to a network, and can communicate with each other.
The main difference between a controller and a datastore is that during power-failure the controller loses its state, while the datastore does not. Hardware failures affect both the controllers and the datastores, rendering them useless (we don’t consider Byzantine failures).
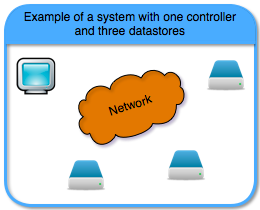
Of course, there could be multiple controllers in a system, especially when we want the system to be tolerant to controllers’ failures. However, in such a system only one of the controllers will be the single writer. For brevity, let’s just call it “the writer” (instead of “the single writer”).
The Algorithm
The writer keeps track of a version number, which is increased by one on each write. When a controller becomes the writer, it is notified via a becomeWriter callback, which provides a version number higher than all previously used. During read the writer requests the existing value from a majority of datastores, and during write the writer sends the new value to a majority of datastores; this scheme is based on the majority read/write, or quorum read/write.
For brevity, the code below assumes:
- that the different operations (read, write, becameWriter) do not run concurrently. They’re executed one after the other, protected by a mutex, or some other serialization mechanism.
- that each response is “attached” to its request, so that a sender cannot receive an old response to a new request.
Controller Code:
read() { read (value, version) form all datastores; return the value with the highest version; } write(new_value) { write (new_value, version) to all datastores; wait for a majority of the datastores to ack; version++; } becameWriter(new_version) { version = new_version; write(read()); // This ensures the value just read // has the new version attached to it. }
Datastore’s Code:
read() { read (value, version) from disk and return it; } write(new_value, new_version) { if (new_version > current_version) { write (new_value, new_version) to disk; return ack to the writer; } }
Note: If there is a power failure during the datastore’s write, we expect it (when it comes back to life) to retain either the old (value, version) pair, or the new one. Implementing this ability will probably require some journaling, or double buffering, and is outside the scope of this post.
To get a sense of the algorithm, consider the following flow, in which during the write operation, the third datastore undergoes a power failure, while during the read operation, the second datastore undergoes a power failure. Thus, the writer gets different values during the read operation, and selects the one that has the the most up-to-date version.
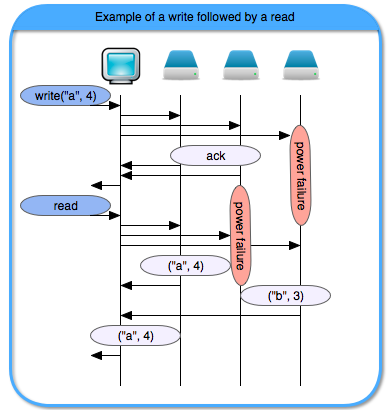
Notice that similar flows might occur due to datastores (or their disks) being slow or due to network issues, rather than actual power failures.
Why Does It Work?
During a period where the writer doesn’t fail, it writes to a majority, and reads from a majority. Thus ensuring there is an intersection between the datastores it has written to, and those that it is reading from. By selecting the value with the highest version (which is also the version the writer keeps), the writer returns the most up-to-date value from the datastores – which is the latest value it wrote.
If the writer does fail, then once a new controller becomes the writer, the first thing it does (in becomeWriter) is to ensure the highest version written in the datastores is the one the writer itself has. This “locks out” all previous intermediate write operations (that might have been partially written).
That is, every time a writer changes, it ensures there is a stable state of the value and version in the datastores. During periods when the writer doesn’t fail, this stable state is preserved. Thus, all in all, reads and writes behave as expected.
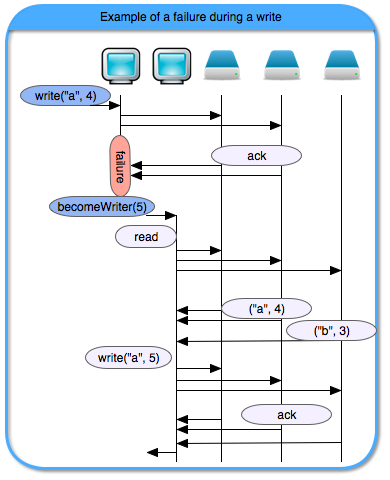
Let’s look at an example where the writer fails mid-write. In this example, there are two controllers, the first one is the writer, and when it fails the other controller becomes the writer. When the other controller becomes a writer, it receives the a version higher than previous ones (in the example it is 5). Then it reads the values from the datastores and takes the value with the highest version amongst them (in the example it is “a”). Lastly, it writes back this value with the new version.
Example Use-cases
Ensuring there is a single writer requires some heavy lifting by an external entity. The process might involve notifying all the datastores to stop accepting requests from the old writer, telling the new writer to start, and somehow keeping track of the versions already used. All of that, in a persistent, highly available manner.
Guaranteeing there is a single writer can be achieved manually, by ensuring the previous writer is down (for example, by pulling the power). It might not provide the best HA support, but it is very simple. Alternatively, the external entity can be a consensus-based configuration service, which monitors the writer, notices the failure, and kicks in the replacement.
Keeping track of the versions being used can be done by splitting the version into high-bits and low-bits, where the high-bits are increased each time there is a new writer and the low-bits are increased on every write. If the version is large enough (say, there are at least 64 low-bits), then this is a simple and sufficient solution. Alternatively, the writer can be allocated dynamic ranges (say 10K versions in each range), but this solution requires replenishing the ranges when the writer uses up the allocated versions; and might be to complex to be worth it.
If there is already a consensus in place why not use it for the read/write service to start with? First, that’s definitely a viable option. Second, the consensus process might be too slow for the task (requiring multiple rounds of communication and disk IOs). Third, consensus is a more complicated algorithm with intricate behavior and requirements – if your setting allows for simpler fault tolerance, it might be worth to have both consensus for configuration management and a single-writer where possible.
TL;DR;
A simple distributed service supporting read/write operations, can be easily made to be highly-available and fault tolerant, under the assumption that at any given point in time there is a single controller (a.k.a. “the writer”) performing the read/write operations.
Additional Remarks
- The datastore’s code for write compares the version from the writer, to the version the datastore has locally. This is needed if requests from the writer might get reordered or duplicated. Assuming there is a single request at a time, and assuming some FIFO channel (i.e., TCP), this protection is not needed, as it can never occur.
- The presented algorithm keeps the value in the datastore, and the writer needs to re-read it each time. In some cases it makes sense to store the value in the writer’s memory, and avoid the need to communicate with the datastores during a read operation.
- The writer has a single version, and a single value. When extending to multiple values, the datastores will need to keep a version per value, but the writer can have a single version. In this case, either a new writer re-writes all the values when it becomes the writer; or, alternatively, it can re-write a value the first time it is read.
